Introducing TensorFlow Similarity
Extracto
Today we are releasing the first version of TensorFlow Similarity, a python package designed to make it easy and fast to train similarity models using
Resumen
Resumen Principal
TensorFlow Similarity representa una innovadora herramienta diseñada para simplificar y acelerar el desarrollo de modelos de aprendizaje automático enfocados en tareas de similitud. Este paquete Python, lanzado en su primera versión, se integra estratégicamente con el ecosistema TensorFlow para ofrecer una solución especializada en el entrenamiento eficiente de modelos que pueden determinar qué tan similares son diferentes elementos, como imágenes, textos o cualquier tipo de datos representados en espacios vectoriales. La importancia de esta herramienta radica en su capacidad para abordar problemas fundamentales en áreas como búsqueda semántica, sistemas de recomendación, verificación biométrica y agrupamiento inteligente. La solución proporciona componentes optimizados que permiten a los desarrolladores y científicos de datos implementar rápidamente arquitecturas de redes neuronales especializadas en aprender representaciones métricas significativas. Esto incluye funcionalidades avanzadas para calcular distancias entre embeddings, gestionar índices de búsqueda eficientes y evaluar el rendimiento de modelos mediante métricas específicas de similitud. La arquitectura modular del paquete facilita la experimentación con diferentes enfoques de entrenamiento mientras mantiene la compatibilidad con las mejores prácticas del aprendizaje profundo.
Elementos Clave
- Arquitectura especializada: El paquete incluye componentes preconstruidos para entrenar modelos que aprenden representaciones métricas, eliminando la necesidad de implementar desde cero soluciones complejas de similitud
- Integración TensorFlow: Diseñado como extensión nativa de TensorFlow, aprovechando su infraestructura de computación distribuida y optimizaciones para acelerar el entrenamiento de modelos
- Métricas de evaluación específicas: Incorpora herramientas especializadas para medir la calidad de los modelos de similitud, incluyendo precisiones tipo k-nearest neighbors y curvas de recuperación
- Indexación eficiente: Proporciona estructuras de datos optimizadas para almacenar y buscar embeddings de alta dimensionalidad con tiempos de respuesta mínimos
Análisis e Implicaciones
El lanzamiento de TensorFlow Similarity democratiza el acceso a tecnologías de vanguardia en aprendizaje de similitud, permitiendo que organizaciones de diversos tamaños implementen soluciones avanzadas sin requerir expertise especializado en métricas de aprendizaje. Esta herramienta tiene el potencial de acelerar significativamente el desarrollo de aplicaciones inteligentes que dependen de comparaciones semánticas precisas.
Contexto Adicional
La creciente demanda de sistemas que comprendan relaciones semánticas entre datos hace que herramientas como TensorFlow Similarity sean fundamentales para el avance de aplicaciones en inteligencia artificial moderna. Su enfoque en la simplicidad y velocidad lo posiciona como un recurso valioso para investigadores y profesionales que buscan implementar soluciones de similitud a gran escala.
Contenido
Posted by Elie Bursztein and Owen Vallis, Google
Today we are releasing the first version of TensorFlow Similarity, a python package designed to make it easy and fast to train similarity models using TensorFlow.
 |
| Examples of nearest neighbor searches performed on the embeddings generated by a similarity model trained on the Oxford IIIT Pet Dataset |
The ability to search for related items has many real world applications, from finding similar looking clothes, to identifying the song that is currently playing, to helping rescue missing pets. More generally, being able to quickly retrieve related items is a vital part of many core information systems such as multimedia searches, recommender systems, and clustering pipelines.
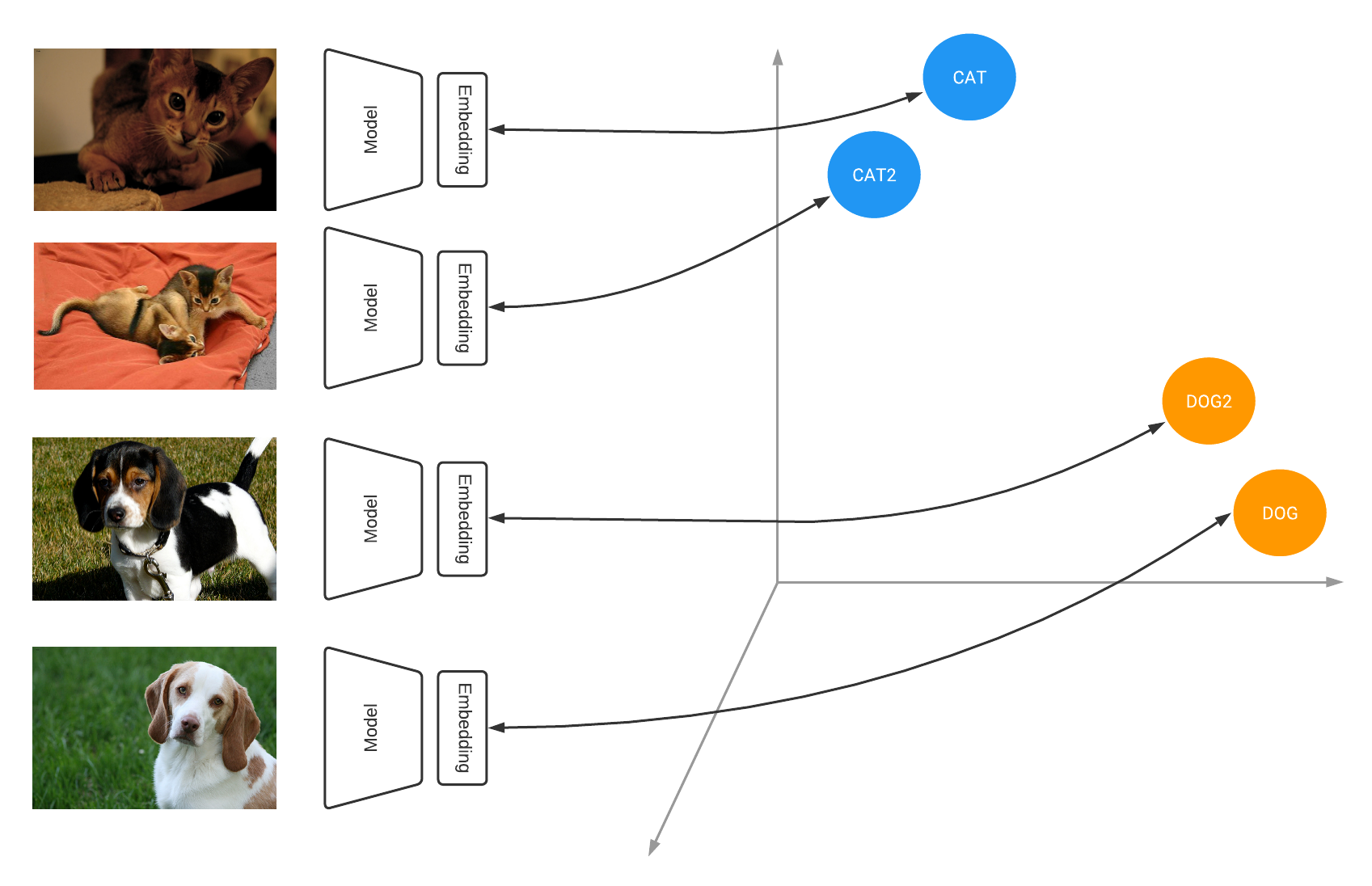 |
| Similarity models learn to output embeddings that project items in a metric space where similar items are close together and far from dissimilar ones |
Under the hood, many of these systems are powered by deep learning models that are trained using contrastive learning. Contrastive learning teaches the model to learn an embedding space in which similar examples are close while dissimilar ones are far apart, e.g., images belonging to the same class are pulled together, while distinct classes are pushed apart from each other. In our example, all the images from the same animal breed are pulled together while different breeds are pushed apart from each other.
 |
| Oxford-IIIT Pet dataset visualization using the Tensorflow Similarity projector |
When applied to an entire dataset, contrastive losses allow a model to learn how to project items into the embedding space such that the distances between embeddings are representative of how similar the input examples are. At the end of training you end up with a well clustered space where the distance between similar items is small and the distance between dissimilar items is large. For example, as visible above, training a similarity model on the Oxford-IIIT Pet dataset leads to meaningful clusters where similar looking breeds are close-by and cats and dogs are clearly separated.
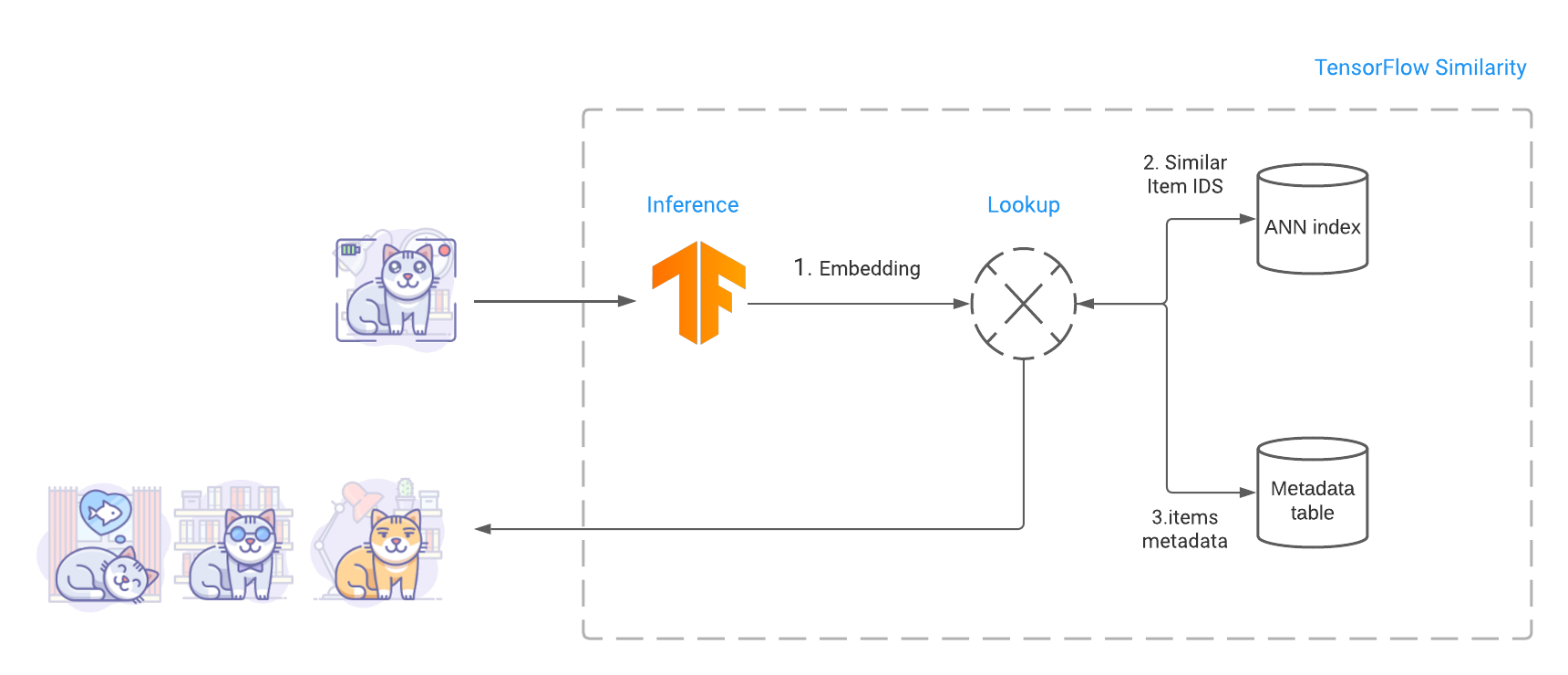 |
| Finding related items involve computing the query image embedding, performing an ANN search to find similar items and fetching similar items metadata including the images bytes. |
Once the model is trained, we build an index that contains the embeddings of the various items we want to make searchable. Then at query time, TensorFlow Similarity leverages Fast Approximate Nearest Neighbor search (ANN) to retrieve the closest matching items from the index in sub-linear time. This fast look up leverages the fact that TensorFlow Similarity learns a metric embedding space where the distance between embedded points is a function of a valid distance metric. These distance metrics satisfy the triangle inequality, making the space amenable to Approximate Nearest Neighbor search and leading to high retrieval accuracy.
Other approaches, such as using model feature extraction, require the use of an exact nearest neighbor search to find related items and may not be as accurate as a trained similarity model. This prevents those methods scaling as performing an exact search requires a quadratic time in the size of the search index. In contrast, TensorFlow Similarity’s built-in Approximate Nearest Neighbor indexing system, which relies on the NMSLIB, makes it possible to search over millions of indexed items, retrieving the top-K similar matches within a fraction of second.
Beside accuracy and retrieval speed, the other major advantage of similarity models is that they allow you to add an unlimited new number of classes to the index without having to retrain. Instead you only need to compute the embeddings for representative items of the new classes and add them to the index. This ability to dynamically add new classes is particularly useful when tackling problems where the number of distinct items is unknown ahead of time, constantly changing, or is extremely large. An example of this would be enabling users to discover newly released music that is similar to songs they have liked in the past.
TensorFlow Similarity provides all the necessary components to make similarity training evaluation and querying intuitive and easy. In particular, as illustrated below, TensorFlow Similarity introduces the SimilarityModel(), a new Keras model that natively supports embedding indexing and querying. This allows you to perform end-to-end training and evaluation quickly and efficiently..
A minimal example that trains, indexes and searches on MNIST data can be written in less than 20 lines of code:
from tensorflow.keras import layers
# Embedding output layer with L2 norm
from tensorflow_similarity.layers import MetricEmbedding
# Specialized metric loss
from tensorflow_similarity.losses import MultiSimilarityLoss
# Sub classed keras Model with support for indexing
from tensorflow_similarity.models import SimilarityModel
# Data sampler that pulls datasets directly from tf dataset catalog
from tensorflow_similarity.samplers import TFDatasetMultiShotMemorySampler
# Nearest neighbor visualizer
from tensorflow_similarity.visualization import viz_neigbors_imgs
# Data sampler that generates balanced batches from MNIST dataset
sampler = TFDatasetMultiShotMemorySampler(dataset_name='mnist', classes_per_batch=10)
# Build a Similarity model using standard Keras layers
inputs = layers.Input(shape=(28, 28, 1))
x = layers.Rescaling(1/255)(inputs)
x = layers.Conv2D(64, 3, activation='relu')(x)
x = layers.Flatten()(x)
x = layers.Dense(64, activation='relu')(x)
outputs = MetricEmbedding(64)(x)
# Build a specialized Similarity model
model = SimilarityModel(inputs, outputs)
# Train Similarity model using contrastive loss
model.compile('adam', loss=MultiSimilarityLoss())
model.fit(sampler, epochs=5)
# Index 100 embedded MNIST examples to make them searchable
sx, sy = sampler.get_slice(0,100)
model.index(x=sx, y=sy, data=sx)
# Find the top 5 most similar indexed MNIST examples for a given example
qx, qy = sampler.get_slice(3713, 1)
nns = model.single_lookup(qx[0])
# Visualize the query example and its top 5 neighbors
viz_neigbors_imgs(qx[0], qy[0], nns)Even though the code snippet above uses a sub-optimal model, it still yields good matching results where the nearest neighbors clearly looks like the queried digit as visible in the screenshot below:

This initial release focuses on providing all the necessary components to help you build contrastive learning based similarity models, such as losses, indexing, batch samplers, metrics, and tutorials. TF Similarity also makes it easy to work with the Keras APIs and use the existing Keras Architectures. Moving forward, we plan to build on this solid foundation to support semi-supervised and self-supervised methods such as BYOL, SWAV, and SimCLR.
You can start experimenting with TF Similarity right away by heading to the Hello World tutorial. For more information you can check out the project Github.