NIM for Developers
Extracto
Run AI models on NVIDIA GPUs in the cloud, data center, workstations, and PCs.
Contenido
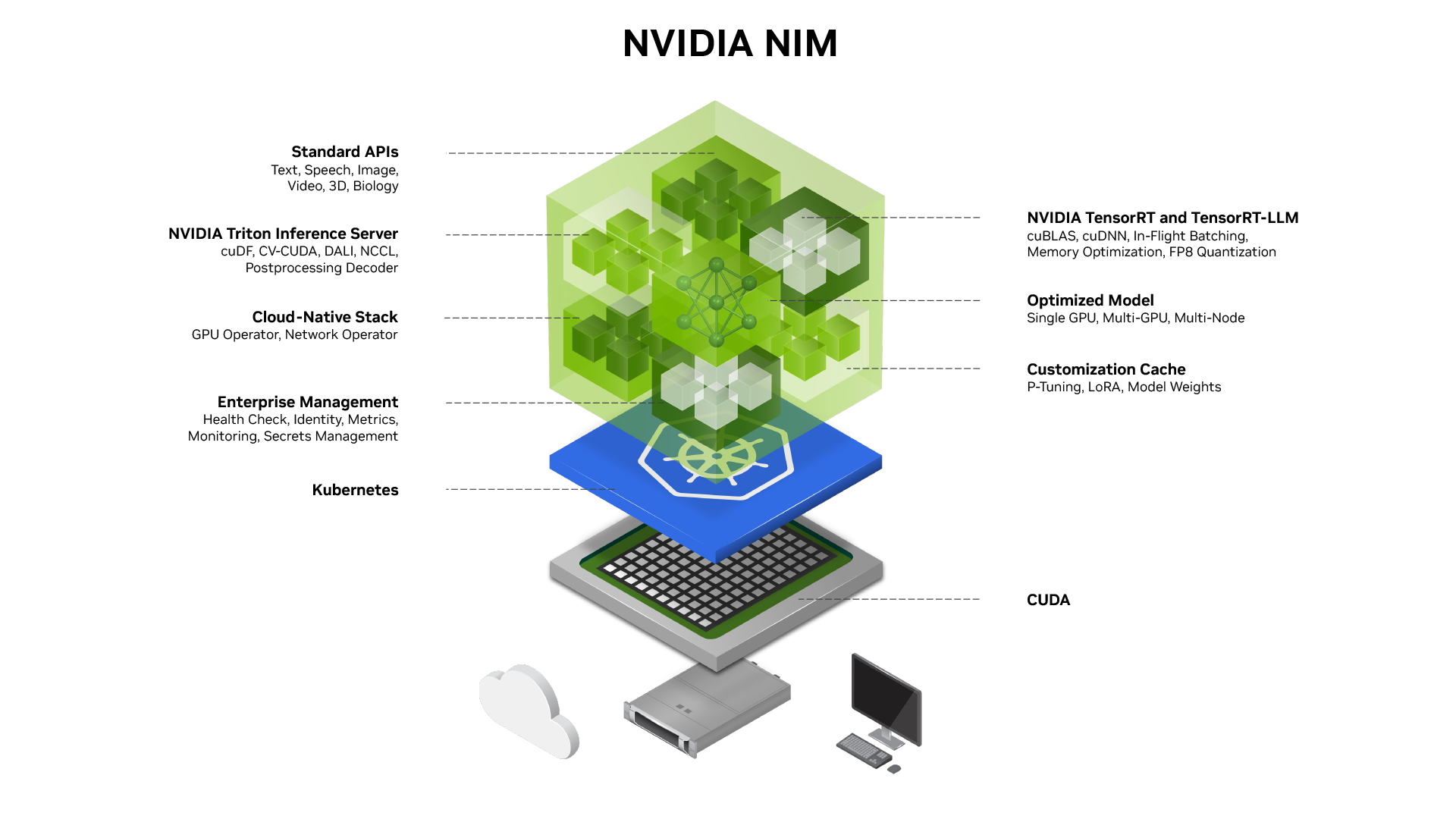
NVIDIA NIM™, part of NVIDIA AI Enterprise, provides containers to self-host GPU-accelerated inferencing microservices for pretrained and customized AI models across clouds, data centers, and workstations. Upon deployment with a single command, NIM microservices expose industry-standard APIs for simple integration into AI applications, development frameworks, and workflows. Built on pre-optimized inference engines from NVIDIA and the community, including NVIDIA® TensorRT™ and TensorRT-LLM, NIM microservices automatically optimize response latency and throughput for each combination of foundation model and GPU system detected at runtime. NIM containers also provide standard observability data feeds and built-in support for autoscaling on Kubernetes on GPUs.
How It Works
NVIDIA NIM helps overcome the challenges of building AI applications, providing developers with industry-standard APIs for building powerful copilots, chatbots, and AI assistants while making it easy for IT and DevOps teams to self-host AI models in their own managed environments. Built on robust foundations, including inference engines like TensorRT, TensorRT-LLM, and PyTorch, NIM is engineered to facilitate seamless AI inferencing at scale.
Introductory Blog
Learn about NIM’s architecture, key features, and components.
Documentation
Access guides, API reference information, and release notes.
Introductory Video
Learn how to deploy NIM on your infrastructure using a single command.
Deployment Guide
Get step-by-step instructions for self-hosting NIM on any NVIDIA accelerated infrastructure.
Build With NVIDIA NIM
Get Superior Model Performance
Improve AI application performance and efficiency with accelerated engines from NVIDIA and the community, including TensorRT, TensorRT-LLM, and more—prebuilt and optimized for low-latency, high-throughput inferencing on specific NVIDIA GPU systems.
Run AI Models Anywhere
Maintain security and control of applications and data with prebuilt microservices that can be deployed on NVIDIA GPUs anywhere—workstation, data center, or cloud. Download NIM inference microservices for self-hosted deployment, or take advantage of dedicated endpoints on Hugging Face to spin up instances in your preferred cloud.
Customize AI Models for Your Use Case
Improve accuracy for specific use cases by deploying NIM inference microservices for models fine-tuned with your own data.
Maximize Operationalization and Scale
Get detailed observability metrics for dashboarding, and access Helm charts and guides for scaling NIM on Kubernetes.
NVIDIA NIM Examples
RAG-LLM
Self-Host AI
Deploy on the Cloud via Hugging Face
Build RAG Applications With Standard APIs
Get started prototyping your AI application with NIM hosted in the NVIDIA API catalog. Using generative AI examples from GitHub, see how to easily deploy a retrieval-augmented generation (RAG) pipeline for chat Q&A using hosted endpoints. Developers can get 1,000 inference credits free on any of the available models to begin developing their application.
Self-Host AI Models as a Service
Using a single optimized container, you can easily deploy NIM in under five minutes on accelerated NVIDIA GPU systems in the cloud, in the data center, or on workstations and PCs. Follow these simple instructions to deploy a NIM container and build an application using connectors from leading developer tools.
Deploy NIM on Cloud via Hugging Face
Simplify and accelerate the deployment of generative AI models on Hugging Face with NIM. With just a few clicks, deploy optimized models like Llama 3 on preferred cloud platforms.
Get Started With NVIDIA NIM
Explore different options for building and deploying optimized AI applications using the latest models with NVIDIA NIM.
NVIDIA NIM Learning Library
Getting Started Blog
Learn how to use NIM microservices APIs across the most popular generative AI application frameworks like Haystack, LangChain, and LlamaIndex.
Benchmarking Guide
Learn how to benchmark deployment of LLMs , popular metrics and parameters, as well as a step-by-step guide.
Documentation
Learn more about high-performance features, applications, architecture, release notes, and more for NVIDIA NIM for LLMs.
More Resources
Ethical AI
NVIDIA’s platforms and application frameworks enable developers to build a wide array of AI applications. Consider potential algorithmic bias when choosing or creating the models being deployed. Work with the model’s developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended.
Learn about the latest NVIDIA NIM models, applications, and tools.
Fuente: NVIDIA Developer