GitHub - blobcity/autoai: Python based framework for Automatic AI for Regression and Classification over numerical data. Performs model search, hyper-parameter tuning, and high-quality Jupyter Notebook code generation.
Extracto
Python based framework for Automatic AI for Regression and Classification over numerical data. Performs model search, hyper-parameter tuning, and high-quality Jupyter Notebook code generation. - Gi...
Resumen
Resumen Principal
AutoAI es un framework desarrollado en Python y alojado en GitHub bajo el repositorio blobcity/autoai, diseñado para automatizar flujos completos de inteligencia artificial orientados a tareas de regresión y clasificación sobre datos numéricos. Este proyecto destaca por su capacidad para ejecutar una búsqueda automática de modelos, realizar un ajuste avanzado de hiperparámetros, y generar automáticamente notebooks de Jupyter con código de alta calidad. La automatización que ofrece AutoAI permite acelerar significativamente el proceso de desarrollo de modelos de machine learning, reduciendo la intervención manual y optimizando la productividad de científicos de datos y desarrolladores. Al enfocarse en datos numéricos, el framework se posiciona como una herramienta especializada para casos de uso donde la precisión y la velocidad en la experimentación son prioritarias. La generación de notebooks no solo documenta el proceso, sino que también facilita la interpretación, personalización y reutilización del modelo resultante.
Elementos Clave
-
Automatización de Modelos de Machine Learning: AutoAI automatiza la selección de modelos adecuados para problemas de regresión y clasificación, eliminando la necesidad de pruebas manuales extensivas y permitiendo una exploración más amplia del espacio de modelos en menos tiempo.
-
Ajuste Inteligente de Hiperparámetros: El framework incluye capacidades avanzadas de hyper-parameter tuning, lo que asegura que los modelos no solo se seleccionen automáticamente, sino que también se optimicen para obtener el mejor rendimiento posible dentro del conjunto de datos proporcionado.
-
Generación Automática de Notebooks Jupyter: Una de las características más destacadas es la capacidad de generar notebooks de Jupyter con código limpio, bien estructurado y listo para ejecutar o modificar, lo cual es especialmente útil para auditoría, colaboración y enseñanza.
-
Enfoque en Datos Numéricos: AutoAI está específicamente diseñado para trabajar con datos numéricos, lo que lo convierte en una solución eficiente y optimizada para dominios donde este tipo de información es predominante, como finanzas, ingeniería o ciencias naturales.
Análisis e Implicaciones
AutoAI representa una evolución significativa en la democratización del machine learning, al permitir que usuarios con distintos niveles de experiencia desarrollen modelos robustos sin tener que lidiar con la complejidad técnica subyacente. Su enfoque automatizado tiene el potencial de reducir tiempos de entrega en proyectos de datos y mejorar la reproducibilidad gracias a la generación de código documentado. Además, al integrar herramientas como Jupyter Notebook, fomenta una cultura de transparencia y colaboración en el desarrollo de modelos.
Contexto Adicional
Este tipo de herramientas se enmarca dentro de la creciente tendencia de AutoML (Automated Machine Learning), que busca hacer accesible la inteligencia artificial a una audiencia más amplia. AutoAI se distingue por su enfoque en simplicidad, calidad del código generado y especialización en datos numéricos, lo que lo convierte en una opción atractiva para entornos donde la precisión y la velocidad son críticas.
Contenido
A framework to find the best performing AI/ML model for any AI problem. Works for Classification and Regression type of problems on numerical data. AutoAI makes AI easy and accessible to everyone. It not only trains the best-performing model but also exports high-quality code for using the trained model.
The framework is currently in beta release, with active development being still in progress. Please report any issues you encounter.
Getting Started
import blobcity as bc model = bc.train(file="data.csv", target="Y_column") model.spill("my_code.py")
Y_column is the name of the target column. The column must be present within the data provided.
Automatic inference of Regression / Classification is supported by the framework.
Data input formats supported include:
- Local CSV / XLSX file
- URL to a CSV / XLSX file
- Pandas DataFrame
model = bc.train(file="data.csv", target="Y_column") #local file
model = bc.train(file="https://example.com/data.csv", target="Y_column") #url
model = bc.train(df=my_df, target="Y_column") #DataFrame
Pre-processing
The framework has built-in support for several data pre-processing techniques, such as imputing missing values, column encoding, and data scaling.
Pre-processing is carried out automatically on train data. The predict function carries out the same pre-processing on new data. The user is not required to be concerned with the pre-processing choices of the framework.
One can view the pre-processing methods used on the data by exporting the entire model configuration to a YAML file. Check the section below on "Exporting to YAML."
Feature Selection
model.features() #prints the features selected by the model
['Present_Price', 'Vehicle_Age', 'Fuel_Type_CNG', 'Fuel_Type_Diesel', 'Fuel_Type_Petrol', 'Seller_Type_Dealer', 'Seller_Type_Individual', 'Transmission_Automatic', 'Transmission_Manual']
AutoAI automatically performs a feature selection on input data. All features (except target) are potential candidates for the X input.
AutoAI will automatically remove ID / Primary-key columns.
This does not guarantee that all specified features will be used in the final model. The framework will perform an automated feature selection from amongst these features. This only guarantees that other features if present in the data will not be considered.
AutoAI ignores features that have a low importance to the effective output. The feature importance plot can be viewed.
model.plot_feature_importance() #shows a feature importance graph
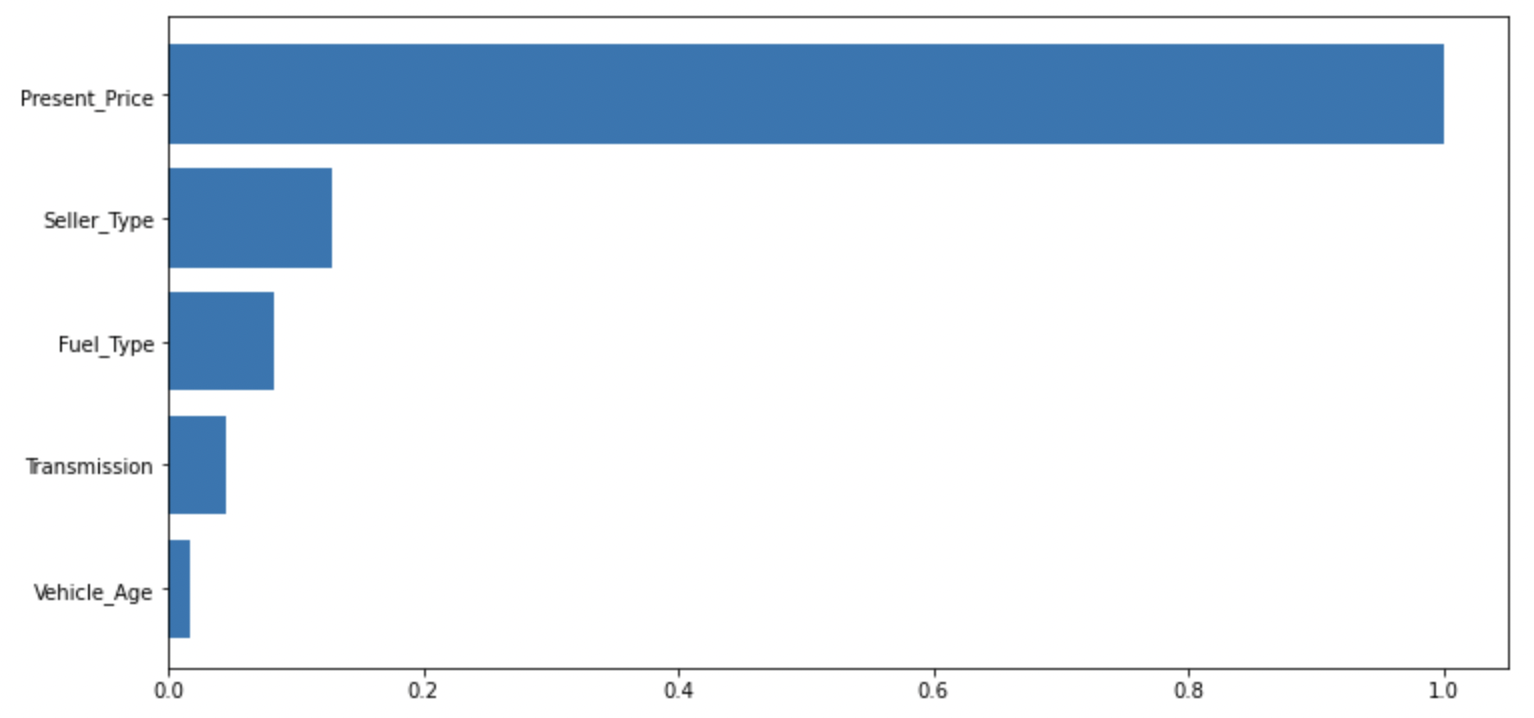
There might be scenarios where you want to explicitely exclude some columns, or only use a subset of columns in the training. Manually specify the features to be used. AutoAI will still perform a feature selection within the list of features provided to improve effective model accuracy.
model = bc.train(file="data.csv", target="Y_value", features=["col1", "col2", "col3"])
Model Search, Train & Hyper-parameter Tuning
Model search, train and hyper-parameter tuning is fully automatic. It is a 3 step process that tests your data across various AI/ML models. It finds models with high success tendency, and performs a hyper-parameter tuning to find you the best possible result.
Code Generation
High-quality code generation is why most Data Scientists choose AutoAI. The spill function generates the model code with exhaustive documentation. scikit-learn models export with training code included. TensorFlow and other DNN models produce only the test / final use code.
Code generation is supported in ipynb and py file formats, with options to enable or disable detailed documentation exports.
model.spill("my_code.ipynb"); #produces Jupyter Notebook file with full markdown docs
model.spill("my_code.py") #produces python code with minimal docs
model.spill("my_code.py", docs=True) #python code with full docs
model.spill("my_code.ipynb", docs=False) #Notebook file with minimal markdown
Predictions
Use a trained model to generate predictions on new data.
prediction = model.predict(file="unseen_data.csv")
All required features must be present in the unseen_data.csv file. Consider checking the results of the automatic feature selection to know the list of features needed by the predict function.
Stats & Accuracy
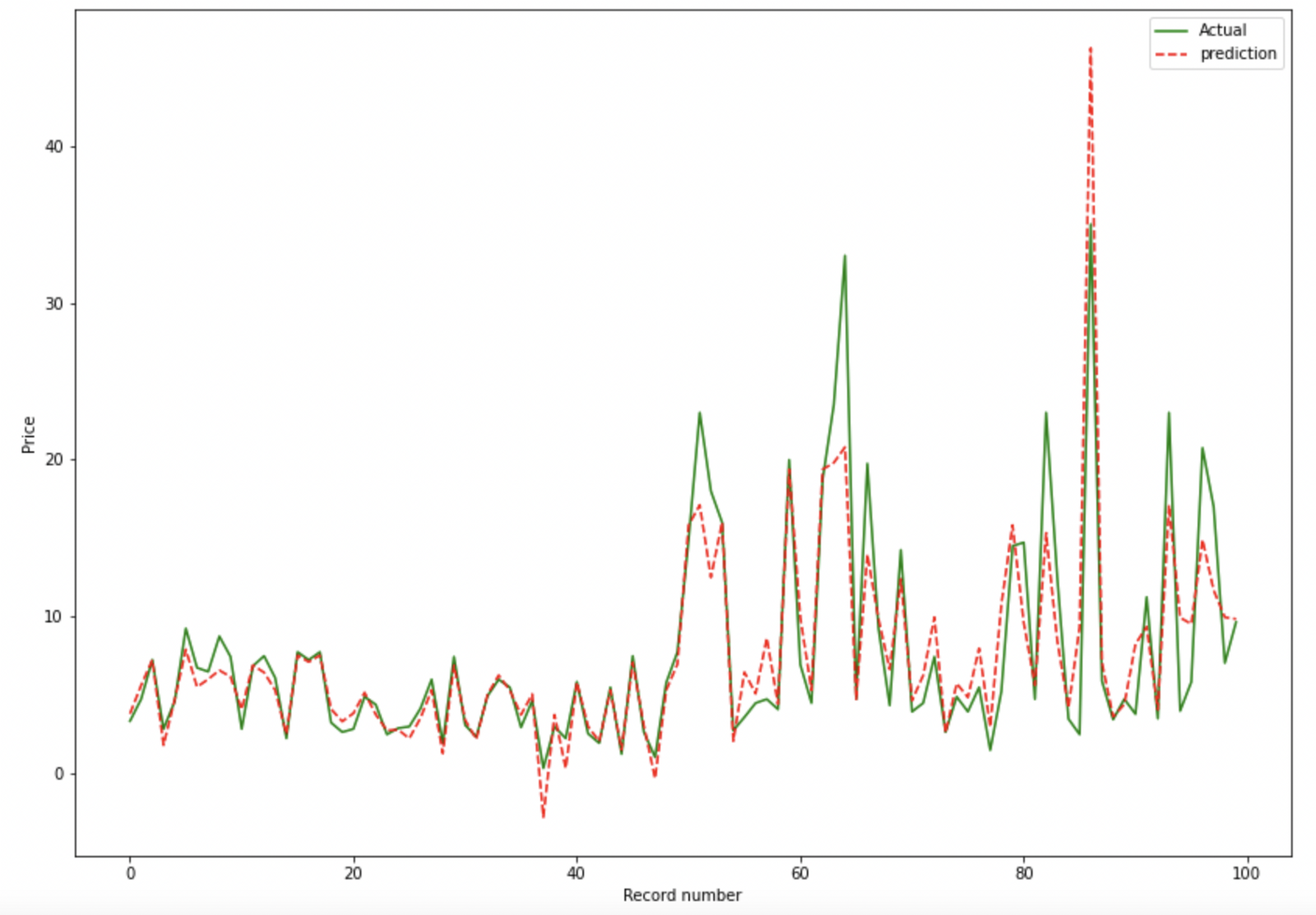
The function is shared across Regression and Classification problems. It plots a relevant chart to assess efficiency of training.
Actual v/s Predicted Plot (for Regression)
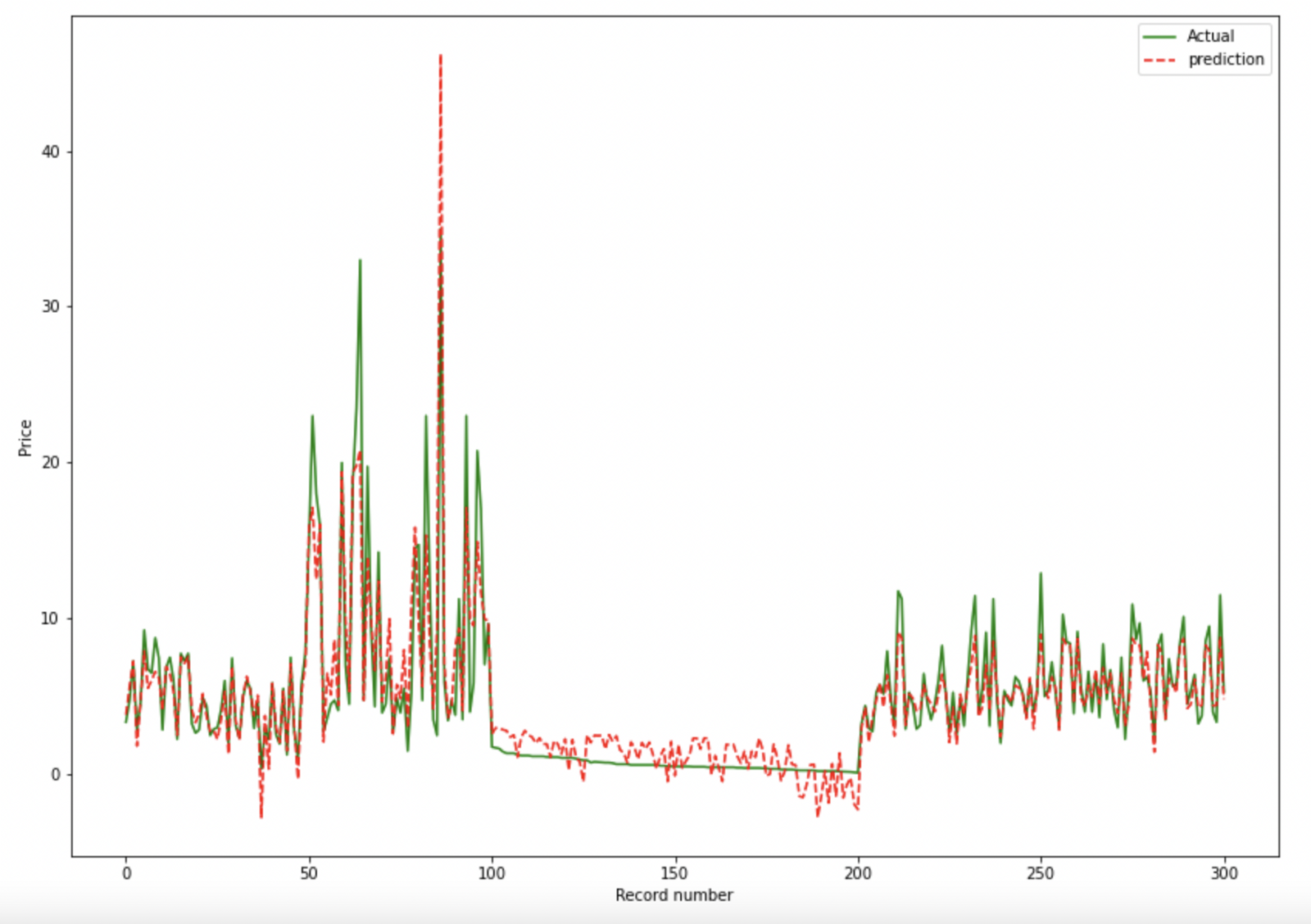
Plotting only first 100 rows. You can specify -100 to plot last 100 rows.
model.plot_prediction(100)
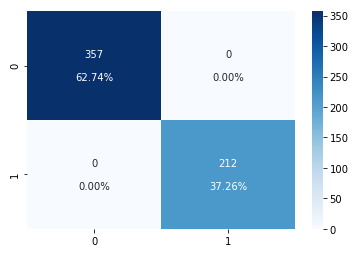
Confusion Matrix (for Classification)
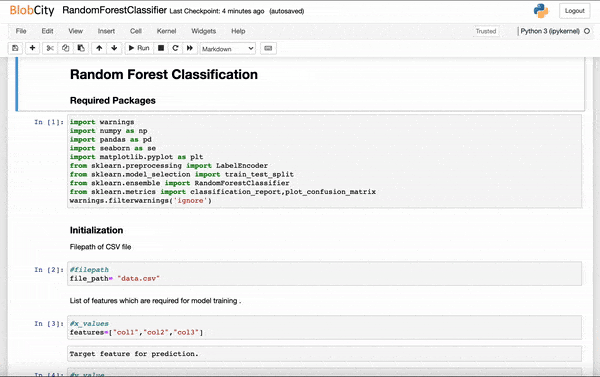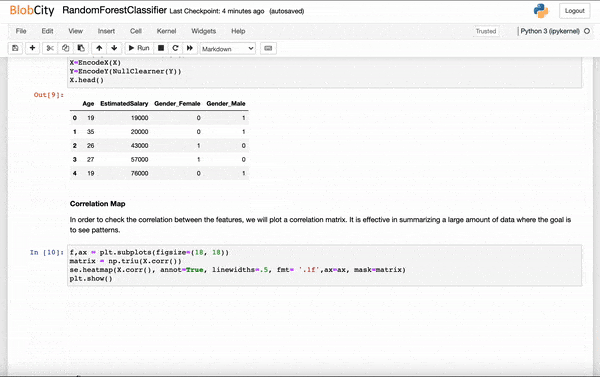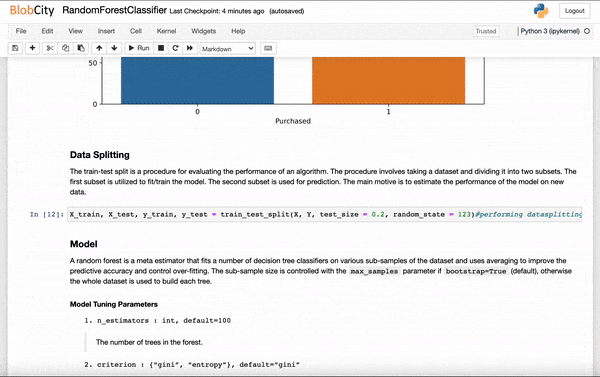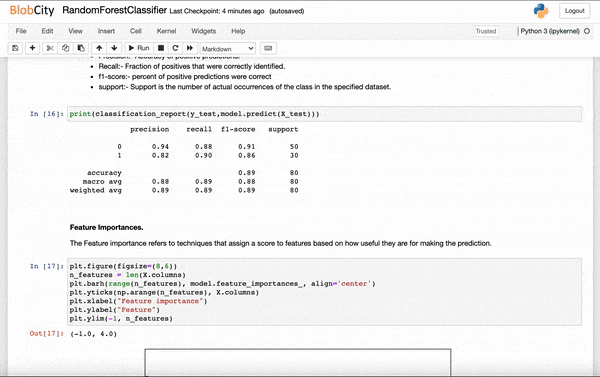
Numercial Stats
Print the key model parameters, such as Precision, Recall, F1-Score. The parameters change based on the type of AutoAI problem.
Persistence
model.save('./my_model.pkl')
model = bc.load('./my_model.pkl')
You can save a trained model, and load it in the future to generate predictions.
Accelerated Training
Leverage BlobCity AI Cloud for fast training on large datasets. Reasonable cloud infrastructure included for free.
Features and Roadmap
- Numercial data Classification and Regression
- Automatic feature selection
- Code generation
- Neural Networks & Deep Learning
- Image classification
- Optical Character Recognition (english only)
- Video tagging with YOLO
- Generative AI using GAN
Fuente: GitHub